The title of this post is based on a question I ask of food consumers every month in my Food Demand Survey (FooDS). If I had to guess your response, I'd go with "spend less." Why? Because every month, for almost four years, that has been the average response to the question (the exact question is: "Do you expect to spend more or less on food bought during grocery shopping in the next two weeks as compared to the previous two weeks?" and response categories are: "I plan to spend about . . . 10% less, 5% less, the same, 5% more, or 10% more").

Here is the problem with the above results. They are almost certainly false. If people are continually, month after month, saying they plan to spend less on food away from home, the cumulative effect would ultimately be a negative amount of spending.
Moreover, another question I ask on the survey relates to how much the respondent says they spend (in dollars) on food away from home (exact question wording: "What has been you (or your household's) usual WEEKLY expense for meals or snacks from restaurants, fast food places, cafeterias, carryout or other such places?" The response categories are: less than $20, $20-$39, . . . $140-$159, $160 or more).
In the most recent issue of FooDS, we estimate the average level of spending on food away from home in January 2017 was $53.26/week. The average answer from the previous month (December 2016) was $50.89/week. So, in terms of stated expenditure, there was a $53.26-$50.89=$2.37 increase (or a (2.37/50.89)*100=4.66% increase). Yet, (and here is the problem), In December 2016, people said they planned to reduce spending on food away from home by, on average, -0.59%, and in January 2017, they said they plan to reduce spending on food away from home by, on average, -1.47%.
Here is what I get if I calculate "actual" changes in reported levels of spending on food away from home against people's stated plans to increase or decrease spending (the blue bars are the same blue bars as in the above graph, they just look different because the vertical axis has been re-scaled).
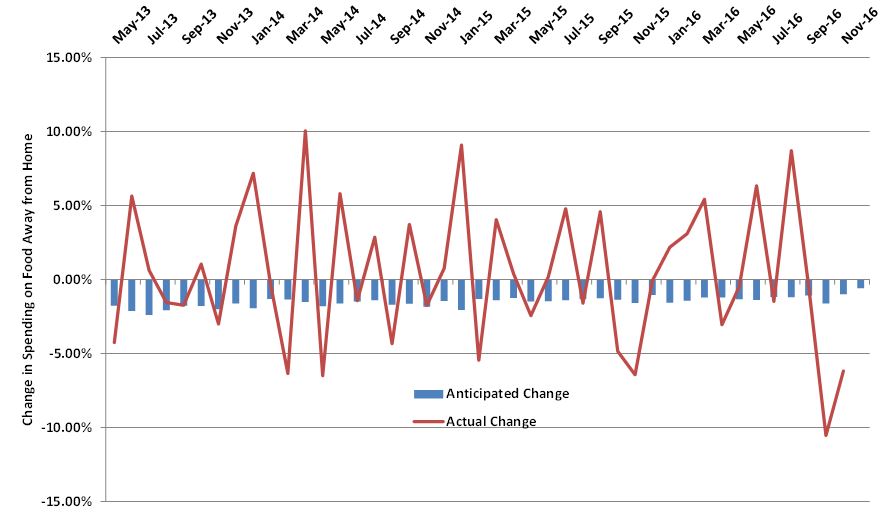
So, what is going on here? One possible answer is that consumers suffer from a type of self-control problem. We tell ourselves we want to reduce the amount we're spending on food away from home in the future. But, when the future arrives, we forget our plans and have fun eating out with our friends and keep spending as usual. If this is correct, eating out is a sort of "guilty pleasure" - something we enjoy but wish we could force our future selves to cut back on.
The propensity of an individual to say they plan to reduce spending on food away from home relates to a variety of demographic variables (even after controlling for the month-to-month effects that may be driving changing spending patterns). Income is a major determinant. Lower income people are much more likely to say they plan to reduce spending on food away from home than higher income respondents. Indeed, for the highest income households, there is no consistent upward or downward bias in planned spending patterns for food away from home. Other (smaller) determinants include gender, age, and participation in food assistance programs with women, older, and SNAP participants being more likely to say they plan to reduce spending on food away from home.
A less nefarious explanation for the above phenomenon might be that our survey is conducted in the middle of the month, and if people are paid at the beginning of the month (or at the end of the previous month), then there might be less remaining in the food budget for "splurges" like spending on food away from home by the time the middle of the month arises and they rationally plan to spend less in the following two weeks.
I doubt this is true for two reasons. The first is that results from other surveys back up the "self control" explanation. For example, this article in the Wall Street Journal a couple years ago pointed to a survey of higher income consumers that asked what kept them from saving more money each month. The most common answer, given by 68% of respondents, was "dining out". The second reasons is that we observe no such phenomenon in our survey for stated changes in spending on food AT home. Here is the average response each month for how consumers expect to change spending on food at home. As can be seen, the value goes up and down and is neither consistently negative or positive.

If you have other explanations for why people consistently say they plan to spend less eating out next month, I'd love to hear them.